- 金宝搏app 可靠吗
- 版本:v3.3.5
- 类别:理财
- 大小:362984KB
- 时间12月02日
金宝搏app 可靠吗:Spark SQL之RDD转换DataFrame的方法
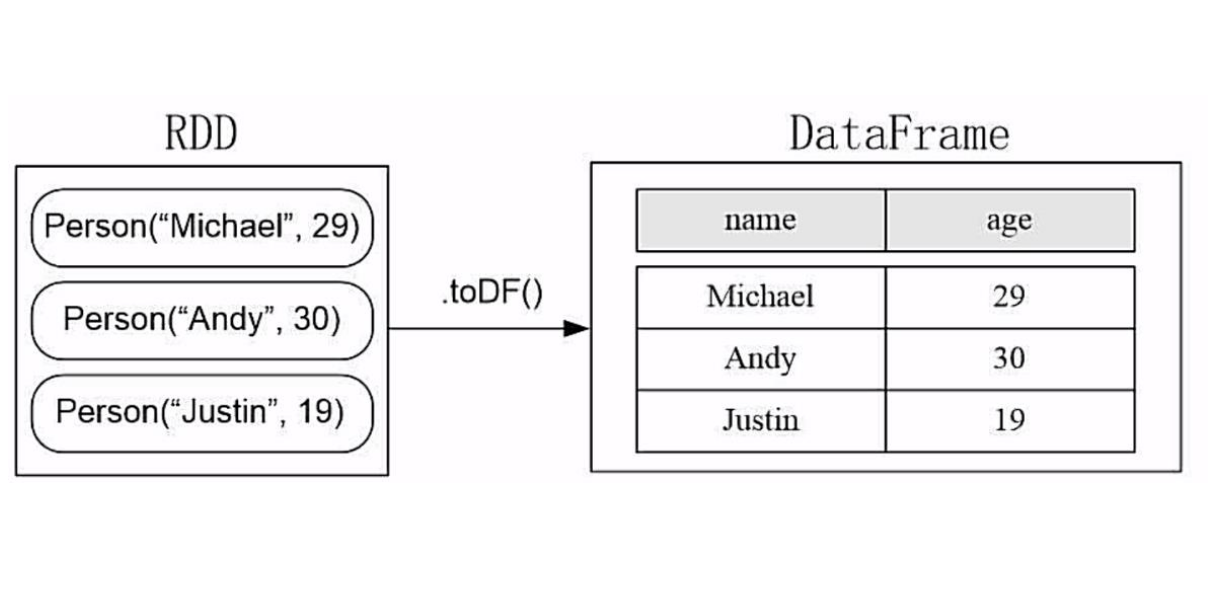
RDD转换DataFrame之Reflection方法
第一种方式是使用反射的方式,用反射去推倒出来RDD里面的schema。这个方式简单,但是不建议使用,因为在工作当中,使用这种方式是有限制的。
对于以前的版本来说,case class最多支持22个字段如果超过了22个字段,我们就必须要自己开发一个类,实现product接口才行。因此这种方式虽然简单,但是不通用;因为生产中的字段是非常非常多的,是不可能只有20来个字段的。
//Java
import金宝搏app 可靠吗 org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import javax.jnlp.PersistenceService;
import javax.xml.crypto.Data;
public class rddtoDFreflectionJava {
public static void main(String[] args) {
SparkSession spark = SparkSession
.builder()
.appName("program")
.master("local").config("spark.sql.warehouse.dir", "file:/Users/zhangjingyu/Desktop/Spark架构/spark-warehouse")
.getOrCreate();
String Path = "file:/Users/zhangjingyu/Desktop/spark-2.4.0/examples/src/main/resources/people.txt";
JavaRDD<PersonJava> personRDD = Spark.read().textFile(Path).javaRDD().map(line -> {
String name = line.split(",")[0];
Long age = Long.valueOf(line.split(",")[1].trim());
PersonJava person = new PersonJava();
person.setName(name);
person.setAge(age);
return person;
});
/**
* JavaRDD<PersonJava> personRdd = Spark.read().textFile(Path).javaRDD().map(new Function<String, PersonJava>() {
* @Override
* public PersonJava call(String line) 金宝搏app 可靠吗throws Exception {
* String name = line.split(",")[0];
* Long age = Long.valueOf(line.split(",")[1].trim());
* PersonJava person = new PersonJava();
* person.setName(name);
* person.setAge(age);
* return person;
* }
* });
*/
Dataset<Row> personDF = Spark.createDataFrame(personRDD,PersonJava.class);
personDF.createOrReplaceTempView("test");
Dataset<Row> ResultDF = Spark.sql("select * from test a where a.age < 30");
ResultDF.show();
JavaRDD<PersonJava> ResultRDD = ResultDF.javaRDD().map(line -> {
PersonJava person = new PersonJava();
person.setName(line.getAs("name"));
person.setAge(line.getAs("age"));
return person;
});
for (PersonJava personJava : ResultRDD.collect()) {
System.out.println(personJava.getName()+":"+personJava.getAge());
}
/**
* JavaRDD<PersonJava> resultRdd = ResultDF.javaRDD().map(new Function<Row, PersonJava>() {
* @Override
* public PersonJava call(Row row) throws Exception {
* PersonJava person = new PersonJava();
* String name = row.getAs("name");
* long age = row.getAs("age");
* person.setName(name);
* person.setAge(age);
* return person;
* }
* });
* resultRdd.foreach(new VoidFunction<PersonJava>() {
* @Override
* public void call(PersonJava personJava) throws Exception {
* System.out.println(personJava.getName()+":"+personJava.getAge());
* }
* });
*/
}
}
//Scala
object rddtoDFreflectionScala {
case class Person(name : String , age : Long)
def main(args: Array[String]): Unit = {
val spark = CommSparkSessionScala.getSparkSession()
val path = "file:/Users/zhangjingyu/Desktop/spark-2.4.0/examples/src/main/resources/people.txt"
import spark.implicits._;
val personDF = spark.sparkContext.textFile(path).map(row => row.split(",")).map(line => {
Person(line(0),line(1).trim.toLong)
}).toDF
personDF.createOrReplaceTempView("test")
val resultDF = spark.sql("select * from test a where a.age > 20")
val resultrdd = resultDF.rdd.map(x =>{
val name = x.getAs[String]("name")
val age = x.getAs[Long]("age")
Person(name,age)
})
for (elem <- resultrdd.collect()) {
System.out.println(elem.name+" : "+ elem.age)
}
}
}
RDD转换DataFrame之Programm方式
创建一个DataFrame,使用编程的方式,这个方式用的非常多。通过编程方式指定schema ,对于第一种方式的schema其实定义在了case class里面了。
//Java
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
金宝搏app 可靠吗import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
import scala.Tuple2;
import java.util.ArrayList;
import java.util.List;
public class rddtoDFprogrammJava {
public static void main(String[] args) {
SparkSession spark = SparkSession
.builder()
.appName("program")
.master("local").config("spark.sql.warehouse.dir", "file:/Users/zhangjingyu/Desktop/Spark架构/spark-warehouse")
.getOrCreate();
String Path = "file:/Users/zhangjingyu/Desktop/spark-2.4.0/examples/src/main/resources/people.txt";
//创建列属性
List<StructField> fields = new ArrayList<>();
StructField structField_name = DataTypes.createStructField("name", DataTypes.StringType, true);
StructField structField_age = DataTypes.createStructField("age", DataTypes.LongType, true);
fields.add(structField_name);
fields.add(structField_age);
StructType scheme = DataTypes.createStructType(fields);
JavaRDD PersonRdd = spark.read().textFile(Path).javaRDD().map(x -> {
String[] lines = x.split(",");
return RowFactory.create(lines[0], Long.valueOf(lines[1].trim()));
});
Dataset<Row> PersonDF = spark.createDataFrame(Pe金宝搏app 可靠吗rsonRdd, scheme);
PersonDF.createOrReplaceTempView("program");
Dataset<Row> ResultDF = spark.sql("select * from program ");
ResultDF.show();
for (Row row : ResultDF.javaRDD().collect()) {
System.out.println(row);
}
}
}
//Scala
import org.apache.spark.sql.Row
import org.apache.spark.sql.types.{LongType, StringType, StructField, StructType}
object rddtoDFprogrammScala {
def main(args: Array[String]): Unit = {
val spark = CommSparkSessionScala.getSparkSession()
val path = "file:/Users/zhangjingyu/Desktop/spark-2.4.0/examples/src/main/resources/people.txt"
val scheme = StructType(Array(
StructField("name",StringType,true),
StructField("age",LongType,true)
val rdd = spark.sparkContext.textFile(path).map(line => line.split(",")).map(x => {
Row(x(0),x(1).trim.toLong)
})
val PersonDF = spark.createDataFrame(rdd,scheme)
PersonDF.createOrReplaceTempView("person")
val resultDF = spark.sql("select * from person a where a.age < 30")
for (elem <- resultDF.collect()) {
System.out.println(elem.get(0)+":"+elem.get(1))
}
}
}
原创作者:张景宇
推荐阅读:
SparkSQL数据抽象与执行过程分享
大数据开发之Spark入门
SparkSQL数据抽象与执行过程分享返回搜狐,查看更多
责任编辑:
相关文章
更多+-
12月02日
-
12月02日
-
12月02日
-
12月02日
-
12月02日
-
12月02日
-
12月02日
-
12月02日
精品推荐
-
乐鱼娱乐网址在线登录:互联网营销师国家职业技能标准来了!带货主播成正式工种下载
-
金宝搏188手机网址:RA官宣FoFo离队 LGD官宣Xiye离队下载
-
千亿网址是什么:证监会连环59问慕思股份:这个洋老头究竟是谁?下载
-
必威betway东盟体育:信源豆豆一招解决“工作群泄密”下载
-
网投十大信誉平台j0500:表演艺术家蓝天野:只要党需要我、观众需要我,我就要发好光和热-_光明网下载
-
网投正规在线平台:原创- 万元羽绒服门店不让退货?加拿大鹅紧急改口,中国消费者还会买单吗下载
-
188金宝搏官网下载:突破7400MB-s,令人惊喜的Kingston FURY叛逆者(Renegade)PCIe 4.0 NVMe SSD下载
-
万博体育maxbextx备用地址:成都链安-爆火的链游是新时代淘金?看懂这些套路避免再被收割!下载
-
BET365下载手机版:勇士召回汤普森 期待“水花兄弟”再合体下载
-
开博体育官网:消费者报告-好欢螺螺蛳粉吃出虫卵,是商业诋毁还是食安问题?下载
-
lehu11乐虎国际:这事儿|深圳卫健委公号再刷爆款,“无套后入有毒”科普防艾知识下载
-
华体会体育app官网下载:助力中国航天梦,看名气电器如何游弋厨电的“星辰大海”下载
-

-

孙子涵 12月02日 15:44
黄金城hjc037vip:职场女性买哪款笔记本?从颜值设计和性能需求出发,我推荐这一款
-
尤韵荔 12月02日 11:32
188金宝搏官方app下载查封了嘛:连环画传颂千年运河 “咱家书房”助力运河原创品牌更亲民-运河品牌+01期-_中国政协_中国
-

仝飞光 12月02日 16:20
金宝搏网页登录:丁磊发布公开信:网易云音乐不止做音乐,还要经营声音的生意-科技频道
-

阳惊骅 12月02日 22:39
千赢国际网址是多少:原创- 比赛日:莱斯特2-2圣徒 那不勒斯遭绝平2-2萨索洛_0
陈渲洋 12月02日 06:52
U乐国际官网登录:中医在泰国:健康“一家亲”- 世界同心圆09-_中国政协_中国